*********THESE PAGES ARE NOW ALL ARCHIVED********
SEE THE CURRENT BLOG AT
SEE THE CURRENT BLOG AT
http://ouseful.info/
July 16, 2008
Visualising CoAuthors in Open Repository Online Papers, Part 3
In Visualising CoAuthors in Open Repository Online Papers, Part 2 I described an approach for pulling author information out of the OU ORO repository and displaying it in various ways, such as using a Graphviz plotted graph. I knew that ORO was scheduling an update, which has been pushed in the last few days, so the screen scraper I wrote to work with the old repository is now broken (of course...). The new ORO engine is capable of generating RSS search feeds though, so looking forwards, the whole system is far easier to play with it...
...but it means that the demos I was just about to post about are now all broken... and it seems that the server I usually post scripts to (http://ouseful.open.ac.uk) won't run the (simple) PHP scraper I was using from the dev server on my laptop, so that's f***d too...
Anyway, had everything been working, I'd have posted about a screenscraper that trashes through results pages from ORO repositories, and generates a .dot graph definition file that can be visualisaed using Graphviz.
Like this excerpt of a view of authors of papers on LB1603 Secondary Education: High schools from the University of Southampton open repository.
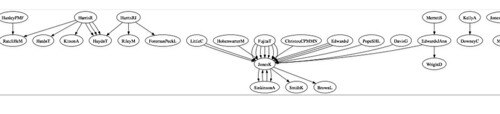
...which I realise just now isn't working properly... the regular expression was tested against the author format used in last week's OU ORO reference listings (where every author was separated by an 'and'), and it breaks for multiple authored papers on the Southampton site where there are more than two authors (only the last author is 'and'ed, the others are comma separated). The fix should be a quick one, but... I have other things to do... and if the OU ORO site has been upgraded, maybe the Southampton one will soon follow...
(It has been pointed out to me that using the approach on e.g. ORO papers might be used to shame people into submitting their own papers to local repositories, when they see their name isn't shown in a particular graph view where they might expect to see it... I couldn't possibly comment on that...!)
Sigh - so much for this as another IWMW innopvation competition entry... The lesson: even sites that nominally use the same software (e.g. eprints) all use them slightly diffefrently; so scraping as a general technique sucks (now I remember why I stopped writing screen scrapers...;-)
The "find collections of sets of names (such as article references), work out all the paired name combinations for each set (reference), then plot the graph" recipe seems to work though...
So for example, here's a graph showing all the people who sit on the same committees in the Isle of Wight Council (as of June 2008); multiple links between two people shows they sit on several different committees together. The direction info in the links is rather more arbitrary, except in two particular cases... if you are only ever the chair of a committee, there will only be links going away from you... If there are only ever incoming links to you, you are not the chair of any committee.
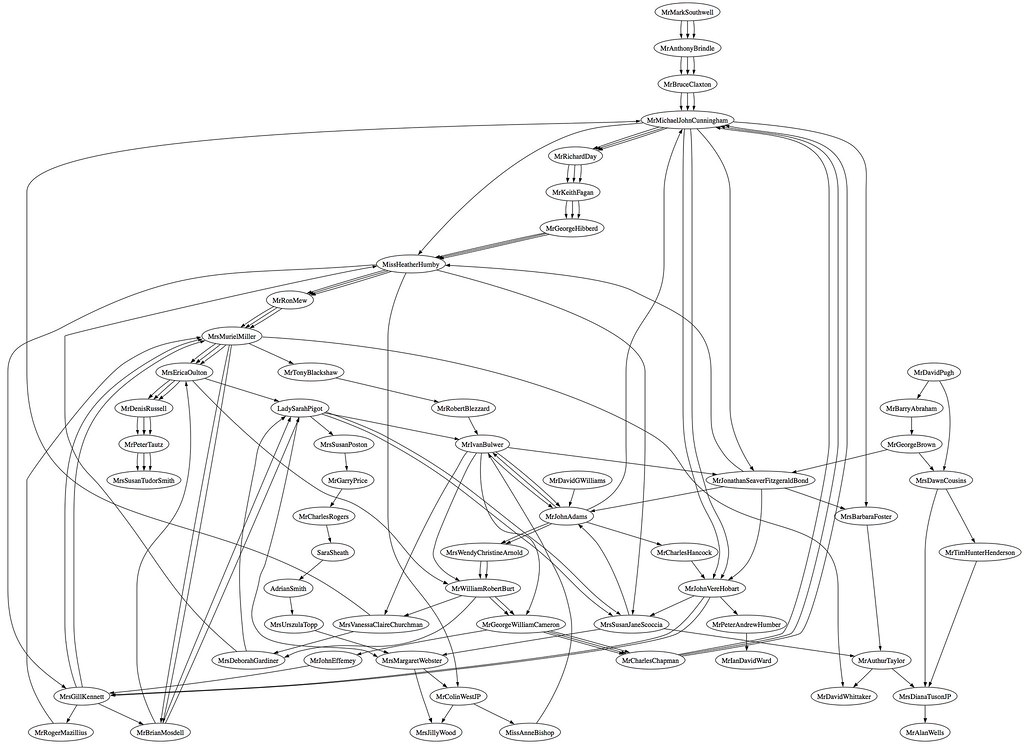
If I could find lists of committee memberships for the OU, I'd have a go at plotting something similar... (it strikes me it might be interesting to see graphs showing named representation on committees that pass work to each other, as well as ex officio membership of committees by virtue of job title/rank (PVC, Dean, HoD, and so on...)
Just one final note - visualising .dot files requires a Graphviz viewer. These are most comonly offline applications, though I have found a coupe of routes to online viewing:
- AJAX Graphviz viewer: post a (small) .dot file into a form, hit the enter key, and see the graph...
- Graphviz filter for Drupal; I had asked Liam if he could get one of these running somewhere, so I could plug in the eprints repository scraper and we'd have a neat IWMW innovation competition entry, but as my scripts all appear to be broken, and I donlt have time to fix them, I guess that's for another day (or not...)..
Anyway, it seems that the OU may be going all 2.0, if Twitter is to be believed... so it's been a good three years or more, and maybe it's job done..?! Time for something else maybe? A return to pointless research in a tiny micro-field somewhere (but at least a promotion prospect at the end...). I'll keep http://ouseful.info pointing somewhere, and http://feeds.feedburner.com/ouseful will keep spewing forth...
...but in the meantime...
OUseful.info on http://blogs.open.ac.uk/Maths/ajh59 has left the house...
...be seeing you...
July 15, 2008
IWMW2008 Innovation Competition - Searching for Media Release Related News Stories
It seems the Institutional Web Management Workshop 2008: Innovation Competition is in need of entries, so I had quick a half hour hack around the University of Aberdeen newsfeeds to see if I could come up with anything interesting (Brian Kelly hinted that if I used any OU info sources, no-one would take any notice becuase it would be seen as an 'official' OU development!;-)
Here's where I've got so far...
The University of Aberdeen (and many other universities) publish an RSS feed of their media releases. But how effective are these releases? That is, do the releases actually manage to generate any news coverage?
University of Aberdeen media releases: http://www.abdn.ac.uk/mediareleases/feed.xml (RSS format, limited to 10 items. ?How can I increase the number of items in this feed?)
One of the easiest ways of doing a news search around an organisation is to simply do a search on Google news.
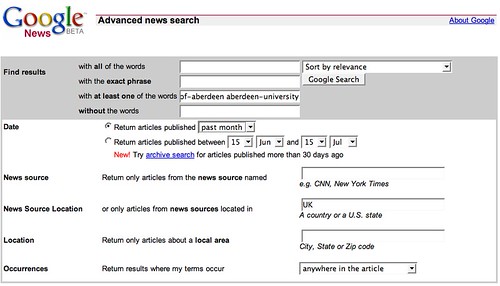
Conveniently, RSS feeds for persistent (alerting) Google News searches are available: Atom feed for Google news search for university-of-aberdeen OR aberdeen-university location:uk over the last month.
That's possibly useful in a different way, though, because it will capture all recent mentions of the university in the UK press.
So here's a recipe that attempts to find news stories about the university that are also on the topics mentioned in the press releases. For convenience, I've specified the recipe as a working prototype in the form Yahoo Pipe.
Fetch the press release feed and run the description of each one through the Yahoo content analysis/term extraction tool.
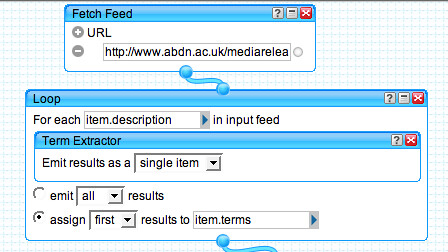
Use these terms as the basis of a search query, supplemented by additional search terms for ("University of Aberdeen" OR "Aberdeen University").

Generate a set of Google news persistent search RSS URLs for UK news mentions over the last 3 months using the above search terms:
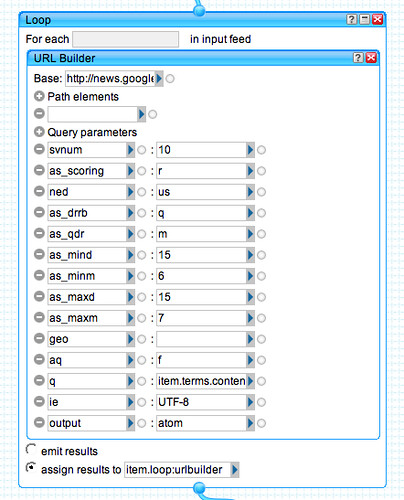
We're now going to replace the original feed items with a set of items returned from the contextualised/media release related news search:
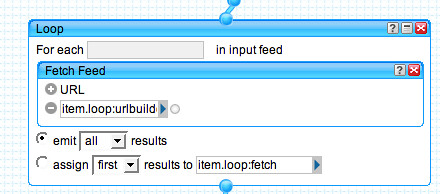
Finally, we use the news story date for the timestamp of each item.
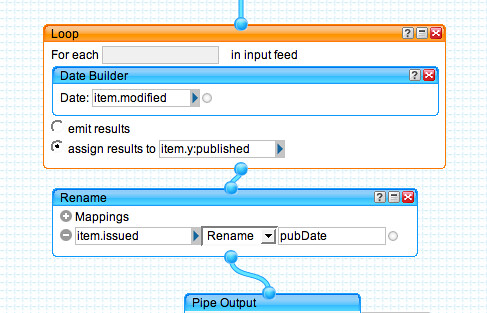
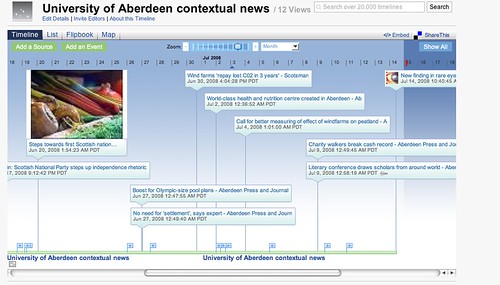
This feed can then be used in the normal way - for example, here it is on a Dipity timeline:
What I need now, of course, is a timeline comparison tool, that lets me compare items on two separate, aligned timelines - one for the media releases, and one for the 'media release contextual news search'...
UPDATE: In the meantime, it's easy enough to merge a feed of the original media releases and the contextual/content extracted terms news search.
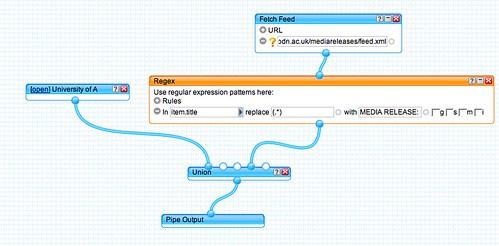
By plotting this feed on a timeline, you can see whether the media release lead to resulting story...
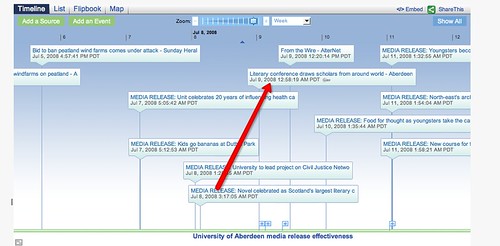
Of course, you'd get an even more comprehensive view if you just plotted a 'raw' news search for "Aberdeen University" OR "University of Aberdeen" (which is what this pipe does, as displayed on this timeline). Which is actually better... Hmm... But this post is about building semantic news filters, right?! (Err... ;-)
So to recap, the idea is to take a university media release news feed, automatically extract a set of keywords related to each media release, and then use those keywords as the basis for a set of queries on Google news for UK based news items related to those topics that also mention the university in question. The results are then output from the pipe as an RSS feed, or otherwise. Each item is timestamped with the date of the news article, so it can be displayed on a timeline, or otherwise, as required.
Note that it would be possible to modify the pipe so that searched for news stories were associated with the media release item that provided the corresponding content extracted query terms that turned up the particular search results. However, to make full use of these results would require a client that could consume and display the JSON output of the pipe, which would take a little bit more time to do... And the point of the innovation competition is that the mashups are quick'n'easy to do, right, and ideally make use of stuff that's already out there?! ;-)
PS another approach might be to search for news stories or blogposts that reference the media release items linked to in the media release feed. For example:
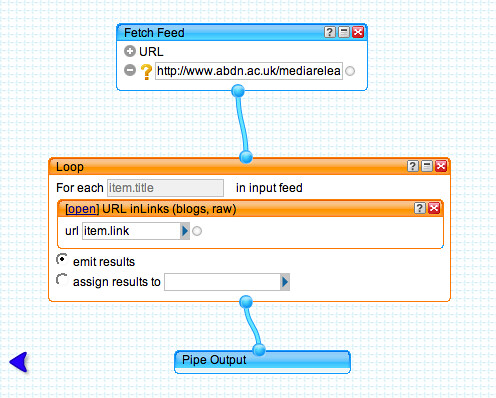
This pipe loops through each item in the media release feed, and searches for blog posts that have linked to the original story (that is, that have linked to the URL for the particular media release).
The "URL inLinks (blogs, raw)" module is one I had built earlier, that uses a Google blogsearch to find posts that mention a particular link. It would probably be more effective to look through each media release to see whatstory related websites (if any) it mentions/links to, and then use these as the basis for the blogged link search (for example, I may not be likely to link to the press release, but I may point to the research group web page it describes).
Tags: iwmw2008, mashup competition, innovation competition
July 11, 2008
Institutional Social Networks
Reading the feed from Michael Webb's Blog yesterday, I was.... stunned is probably the best word, to read his post "Newspace - a social networking site for new students" which describes "a social networking site for new students at the University, http://newstudents.newport.ac.uk." And why was I shocked? "It's based on Ning..." (a site we've also used as an online social network complement to our two recent SocialLearn workshops).
(The actual NIng site is here: http://newportstudents.ning.com/.) Michael's post describes some of the issues relating to the decision to use Ning, and is well worth a read...
Having dutifully emailed(?) the SocialLearn team to give them a heads up about this site, I got a "yeah, it's happening all over the place" reply back that linked to a site the University of Bradfrod have also set up on NIng: Develop Me! (University of Bradfrod on Ning). This social network appears to offer the "Meet and chat online" bit of a wider project hosted on the University of Bradford website itself: Develop Me! homepage
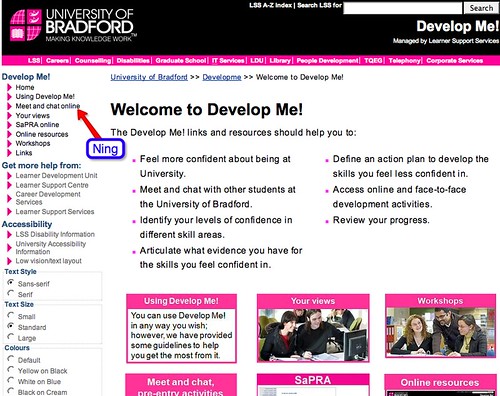
Here's the Bradford site on Ning:
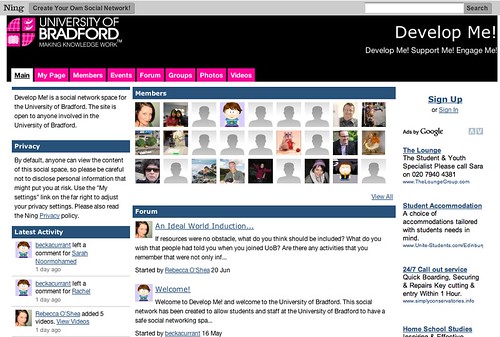
It's interesting how the openness of the front page of this site compares with what happens if you try to go straight to the Newport Ning site...
So with some institutions feeling adventurous and taking the plunge into the world of social web apps, whilst maintaining some element of control, how will SocialLearn fit into all this? Like this maybe?
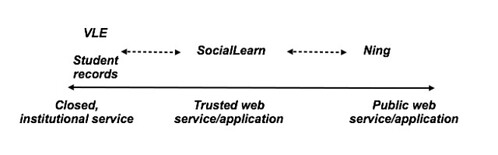
That is, maybe SocialLearn could become a trusted gateway to the world of social networks that institutions are more likely to trust than sites like Ning? By providing an open API and clear security model, it may also provide a platform within which insitutions can develop their own social applications or expose their own data to their own students in a social context? In developing a trusted pltform though, a lot would ride on the structure of the governance model, which is still unclear (at the moment, it's being run within the OU, using external developers, as an OU strategic development project).
PS Just trying to find my first mention of Ning on OUseful.info, I cam across this post from over two years ago now about ad hoc learning environments. Reading back over it, i wish I'd worked some of the ideas through more clearly, because they could well have fed into SocialLearn discussions over the last year...
PPS As well as Ning, let's not forget sites like UK based Webjam, which apparently received funding this week to help roll out its white label social network service...
Tags: ning, sociallearn, socialearn, s:l
Synchronicity in the Air... Institutional Innovation & OU Job Ads
It's been one of those weeks this week when synchronicity (or maybe confluence) seems to have been in the air...
So for example, the week started with brief email exchange regarding knowledge management in the context of tracking and reviewing and getting feedback/opinion on new technology that might be interesting (one might almost say "OUseful";-) in an OU context. Here was my take on it:
Something I feel we need to explore is find a way of helping information "flow" around the university more, routing it to the right people as needed. A few of us do this anyway in an informal way anyway, either as a broadcast (eg public blog) or point-to-point communication "FYI emails"; thing's like the LTS media monthly newsletter also communicate news items to people who are likely to be interested in such things.Then yesterday, John Tropea/Library Clips posted some thoughts on "There’s more than just supply-side KM", (a response to this article on Ideation and the Supply Side of Knowledge): "The article is about how much time and energy we devote to: Capturing and storing vs Knowledge flow...[I]n a learning organisation you are aware of solutions as they happen, even if you have no use for them at the time. You can connect to people involved in the solutions, and you are connected to people in general. The act of participating gives more chance of solutions coming to you more easily… you have more of a chance of shared context and the peripheral information around a solution."As far as soliciting the opinions of OU members about particular technologies, then we need: a) a way of routing these 'call for comments' to people who can comment quickly; b) getting comments back to the people who need them in an appropriate form.
Being lazy, I'd like to be able to do several things at once with any comments I make - eg: a) get the commentary back to who wants it; b) get a blog post out of it ;-) It'd also be nice to think that there was some way of actually seeing new ideas built on and rolled out across the university.
What's needed is to get a conversation going and give people the feeling that they are allowed to spend time indulging/participating in that conversation, which may be with internal people or it may be with the wider world e.g. through online networks. And requests for comments would just be dropped into that conversation somehow...
The original article - by Raj Datta - also has this to say:
[T]hose who believe that "management" is about control and predictability often view KM as a way to bring about predictability, by documenting all best practices and lessons learnt and making them available to everyone.Now where I thought this argument would go was along the lines of: even we do manage to curate information about new technologies effectively, that information is not necessarily going to be worked effectively if that information doesn't continue to circulate - or "flow" - around the organisation, as part of an ongoing conversation within the organisation, in particular the conversation between those people who can benefit from the information, work it further, or work it into conversations with other people who might benefit from it.Here, the supply side becomes focused on explicit knowledge, on identifying and generating quality content, and generally focused on learning from the past. The hidden assumption is that once the right answers are all available in the repository, everyone will come seeking it. Demand, it's assumed, is automatically created. This then produces a robust internal knowledge (content) market, complete with consumers and producers of knowledge (content).
But it didn't, at least not in such crude terms... (Even so, the "flow" argument is still one of the take home messages I'll (mis)remember the article by! )
What the original article does go on to talk about is how organisations potentially miss out on creating new knowledge, because they are too busy mining the past:
But even if one were to subscribe to this viewpoint, it has at least one obvious shortcoming. By equating KM with content management, and by equating the purpose of KM with predictability and control, we may inadvertently de-emphasize new knowledge creation.This line of thinking resonates strongly with me. After almost 10 years here, I still don't understand how the OU manages to take internally produced "inventions" and work them up to a state where they can be delivered as institutional innovations... Although maybe that's about to change?
...[N]ew knowledge creation is about the future. It's about possibilities and alternatives. It's about doing things differently and unleashing creative energies. It's about innovating.Companies that are serious about innovation have to create an organizational ecosystem that allows for creativity to be sourced, transformed into inventions and then into innovations. This forwardlooking view gives KM a new meaning and purpose. Companies that are able to foster new knowledge creation alongside the more traditional view of KM, are able to strike a balance between effectiveness and efficiency and between innovation and productivity. This is a necessary condition for longevity in a global knowledge economy.
Why ideation?
Ideation is the first step in the whole process of innovation. A good way to judge whether a company is serious about innovation is to see what happens to ideas in that company Some indicative questions are: Who is responsible for generating ideas? Once generated, how are ideas transformed to inventions?
If these questions have been explicitly considered in the organization, then chances are that the first step towards a generative view of KM strategy has been taken. This shows that the company values knowledge creation.
If these questions are implicit, or we have to search for the answers, then chances are that a strong enough focus doesn't exist yet in the organization. If the R&D department is viewed as the place where ideation happens and inventions take place, then we are again [li]miting the potential of tapping into the collective creative energies of the organization. R&D personnel are not the only ones with ideas and creative minds, and open processes should exist to tap into the collective capabilities of employees.
As well as creative minds that generate ideas, we also need minds that know how to transform wild ideas into feasible implementation projects and we need minds that are able to understand market potential and how to tap into it. In short, we need to transform ideas to inventions and then inventions to innovations, tapping into the collective insights and capabilities of complementary minds. Base skills, competences and strengths may differ across employees, and by themselves have limited use, but the power of tapping into their collaborative capability is tremendous.
Fascinated by the use of new technologies to enhance the learning experience in higher education? A Learning Innovation Office is being set up within the Open University's Strategy Unit to coordinate the development of elearning and innovative teaching and learning. Building on the University's new virtual learning environment (VLE), the Office will commission and oversee further development work, coordinate elearning strategy and policy, and monitor and disseminate learning innovations at the OU and elsewhere. The Director of Learning Innovation has been appointed and a number of staff are being recruited to work with him.As well as those posts, there is also this rather wonderful sounding post:Excellent organisational, interpersonal and communication skills, flexibility and initiative will be needed by all of the role holders to liaise with a wide range of academic, technical and administrative colleagues. You should have considerable experience of elearning development and implementation.
Change Manager
You will work under the leadership of the Director of Learning Innovation to plan and initiate a range of strategic change initiatives, aimed at promoting elearning and embedding the OU's new VLE across the University. You will need exceptional communication, presentation and project management skills and will have significant experience of coordinating change initiatives in higher education. You will be supported by two Senior Project Managers.Developments Manager
You will work under the leadership of the Director of Learning Innovation to manage the operational activities of the Learning Innovation Office, and to plan and oversee a number of projects to develop additional functionality for the OU's new VLE. These projects will be managed by two Senior Project Managers who will report to you. You will need exceptional project management skills to provide effective management of these initiatives, significant experience in administration related to systems development, and will liaise with colleagues in other units who will be providing the technical and operational management of the VLE.Two Senior Project Managers
The Senior Project Managers will work under the direction of the Developments Manager and Change Manager, Learning Innovation Office, to plan and manage a number of activities aimed at promoting elearning and usage of the VLE, and to manage projects to develop additional functionality. You will report to the Developments Manager in the Learning Innovation office and you will need excellent project management and communication skills and significant experience in administration or systems development to provide effective management of these initiatives.
Director of Multi-Platform Broadcasting, Strategy UnitI'm not sure whether this post in marketing will report in any way to that post, though?
Europe's largest and most innovative university is seeking an outstanding individual for the new post of Director of Multi-Platform Broadcasting, which has been created following a major review of our broadcasting strategy.You will have extensive experience at a senior level in the broadcasting and/or internet sectors and will have the strategic vision, management capability and technical understanding to enable the University to realise the potential of all broadcast media to support its global teaching and learning, research and public engagement missions. You will work closely with the University's Open Broadcasting Unit, with a wide range of areas of the University, and with the BBC and other key partners.
You will be responsible to the Pro Vice Chancellor (Strategy, Planning and External Affairs) for the achievement of the University's ambitious broadcasting objectives.
Marketing Manager, Marketing and SalesBusiness innovation is also in the air:
In this new role has been created to focus on developing marketing plans covering BBC programming, Widening Participation & Openings and other marketing projects. You will work with marketing colleagues in the OU and BBC to scope and identify education and training opportunities for the Widening participation sector, opportunities to promote the BBC and marketing our Openings courses. You will also develop and manage fulfilment of a marketing plan to these markets and identify appropriate channels to market.
Senior Project Manager, Europe. Futures Office, Strategy UnitDisclaimer: none... ;-) Except maybe the OUVS post... I have an idea for an OUVS webservice that's being considered in part under the SocialLearn banner...
We wish to appoint an outstanding individual to the Futures Office, to manage the implementation of the OU's strategy for Europe. You will liaise with key stakeholders across the OU and externally to evaluate and identify the optimum business model for the OU's operations in central Europe, shaping the OU's strategic priorities for international growth.Communications Program Manager (Business to Business), Marketing and Sales
Reporting to the Head of Customer Communications, as part of the sub unit management team, you will lead the planning, development and execution of marketing programs for the business to business segment; targeted to increase OU awareness and to generate enquiries from employers resulting in sponsored students, CPLD (Centre for Professional Learning and Development) revenues, etc.Senior Manager (Administration), Validation Services
Open University Validation Services is responsible for providing Open University validation for external academic programmes; and vocational awards through the OU Awarding Body. More than 33,000 students are currently registered for validated and vocational awards in more than 50 partner organisations. The University is currently investing in a restructure of OUVS and an expansion of our team. As part of our expansion we are seeking a Senior Manager (Administration) to manage central support services including management of registrations, certification and aftercare services.
Needless to say, I have nothing to do with appointments to any of those posts, at the dizzying heights such as they are (I'm way down the food chain, and on the academic side of the fence too...). That said, I'll probably heckle whoever does get in and try to grab a coffee with them every so often!
Tags: recruitment, innovation
July 10, 2008
Visualising CoAuthors in Open Repository Online Papers, Part 2
Having tinkered using Moowheel to visualise coauthors on references pulled from the OU's open repository (ORO) in Visualising CoAuthors in Open Repostory Online Papers, Part 1, to give a graphic which isn't really that useful or interesting (too cluttered), I thought I'd try out a couple of network visualisations using Many Eyes and Graphviz.
It's possible to construct graphs using both these tools by organising the data in pairs - so for each reference in a collection of references (for example, all the papers produced by a particular unit, or all the references returned from a title/abstract search on a particular query term), I pulled out every possible pairwise combination of authors. (So for exampple, a paper authored by A, B, C and D generates (A, B), (A, C), (A, D), (B, C), (B, D), (C, D) as all the possible pairwise coathor relations for that reference.) For convenience (i.e. as a result of laziness), I allowed duplicate pairs into the list (so if A and B had coauthored mutliple papers, their pairwise cauthor relation would appear many times in the data set.
So what's the result? Well here's a Many Eyes view over references produced from the Academic Unit/Department: Educational Policy, Leadership and Lifelong Learning:
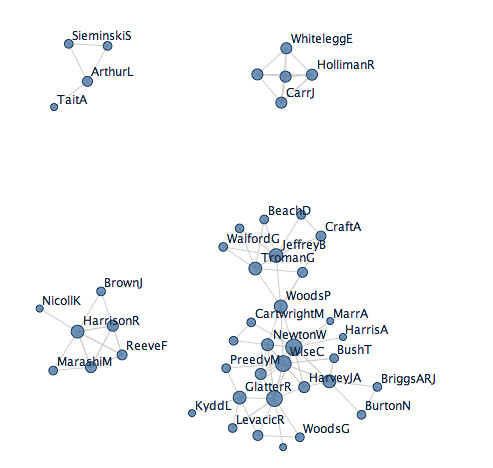
It's possible to zoom in to the display and highlight or search for individual authors, and see who they have co-authored with:
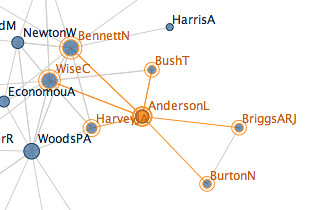
As it seems that Many Eyes now allows visualisations to be embedded, let's see what happens if I try to embed the above.
At a high level, this visualisation allows us to pick out clusters of what we might refer to as different co-authoring teams within the unit. If we were visualising references returned from a search on a particular topic, the result might allow us to detect different groups working in a similar who don't author with each other, or different domains that use the same term but in completely different senses.
There are also a few things to notice in the detail about the Many Eyes network visualisation. Firstly, ambiguity in naming has a visual effect: WoodsPA and WoodsP are the same person I think, so their different representation creates an artificial degree of separation in the visualisation. Secondly, the node size reflects the degree of (I think) each author node - that is, the number of coauthors are connected to. I'm not sure if it also represents the absolute number of times the name appeared in the uploaded data set? Which leads neatly to the third point: the repeated occurrence of the same coauthor pairs are not apparently visualised.
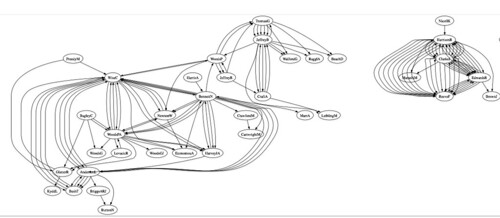
If we now look at a fragment of a Graphviz directed graph (the direction goes from authors who appear earlier in the reference list to authors who appear later) we see that repeated co-author pairings are displayed - the number of connections between two authors represents the number of references they have coauthored:
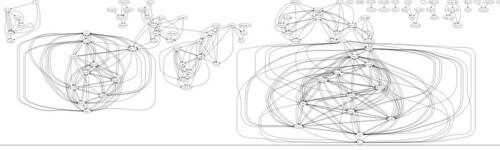
Visualising the results of a search (e.g. a search over ORO for the term "mobile") reveals far more structure - here's a significant fragment of a Graphviz visualisation of couthors on references returned from just such a search:
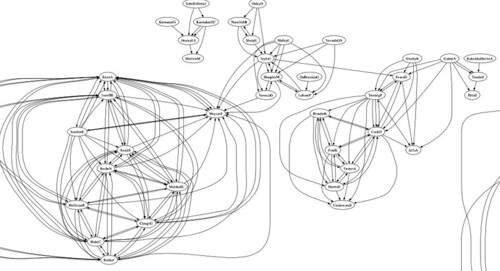
Here's a more detailed view of part of the above:
So what? So nothing really... it just seemed like a good idea at the time, another way of trying to identify professional networks and teams based on their outputs... and it was relatively trivial (and quick) to do... ;-)
Tags: viz, oro, visualisation, graphviz, many eyes
July 09, 2008
Visualising CoAuthors in Open Repostory Online Papers, Part 1
In ORO Search by Name Pipes Interface I described a Yahoo pipe for extracting author information from papers listed in the OU's open repository, and outlined some of the potential author naming ambiguities that arise when using ORO reference data as author metadata. In this post, I'll describe my initial attempt at visualising co-author relations using the Moowheel javascript visualisation library. In a couple of follow on posts, I look at some rather more 'correct' visualisations using both Moowheel and Many Eyes.
If you're not familiar with it, Moowheel constructs a circular display of points that are connected to each other by some relation when provided with a set of data organised in an appropriate way. For example, in delicious Tags'n'users Wheel I used Moowheel to show the tags used by different users who had bookmarked a particular URL on delicious.
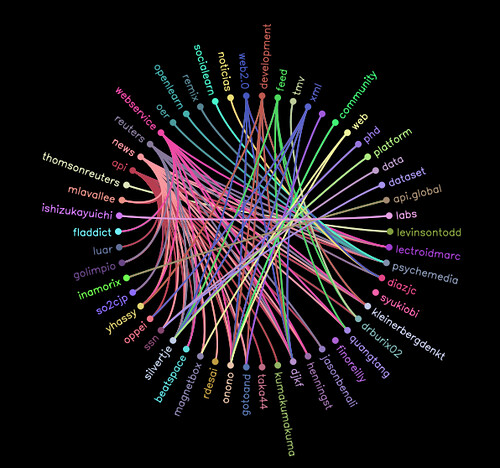
Hovering over a username highlights the tags they used to bookmark the original link.
In Moowheel v0.1 at least, the data must be supplied in a form similar to: (a, b, c), (c, a, d), (b, c, e), (d, a), (e). To construct the circle, each item (a, b, c, d, e) must be present as the first item in a set; each set describes the items that are connected to each other in some way.) Links are highlighted to members of a set when the first item in the set is hovered over.
So here's how I first thought to try to visualise the co-authors of an ORO paper - the source is a results listing for a search on ORO by author "pillinger":
- construct a list of unique authors and use this to create the unique items on the circle: (author1), (author2), (author3), ..., (authorN).
- construct sets of the form: (author1, author2), (author1, author2), ..., (author3, author1, authorN) - where the first set are the authors of paper1, the second set are the authors of paper2, and so on.
My hope was that the Moowheel would then plot out the connections between all the authors who had ever coauthored a paper together that had also included a "pillinger" as an author. Here's a sample result:
You'll see that some authors are depicted multiple times, but with no connections. What Moowheel v0.1, at least, seems to be doing is only display the connections for a non-singleton set where the first term in the set occurs with other set members for the first time(?) (There was also originally some ambiguity in actual author names; for example, "PIllinger, CT", "Pillinger, C" and "Pilinger, Colin" all appear in the results list - see Dirty Name Data in the OU Open Repository Online for a discussion about this; in the above demo, I went overboward and just used the surname, which combined results fro "Pillinger, C" and "Pillinger, J"...;-)
If you want to have a play with the Moowheel, you can find it here: ORO viz demo 1.
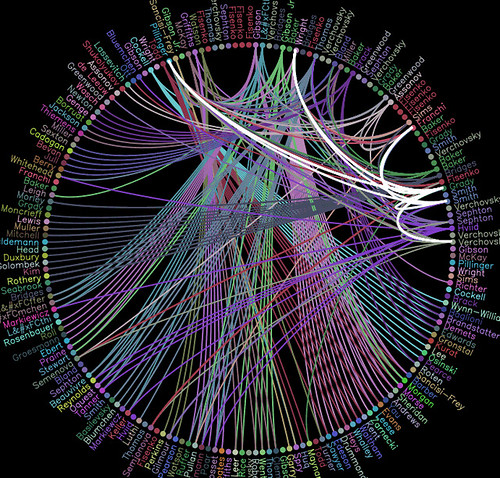
In order to cope with authors appearing multiple times along the outside edges of the graph, I guessed that I needed to construct non-singleton sets that were started with a unique identifier, so I added a level of indirection that related authors with the papers that had contributed to:
- construct a list of unique authors;
- construct sets headed by unique authors, and the papers they had contributed to, and use this to create the unique items on the circle: (author1, paper1, paper2), (author2, paper1), (author3, paper2, paperN), ..., (authorN, paper2).
- construct sets for each paper listing the authors who had contributed to that paper: (paper1, author1, author2), (paper2, author1, author3), ..., (paperN, author3).
Here's the result (ORO viz demo 2 NB there's a niggle somewhere in the code which means that for some few results listings, the wheel doesn't display... Also, the pipe canlt cope with overlong results listings Ideally, ORO would produce it's own RSS/JSON output...:-(:
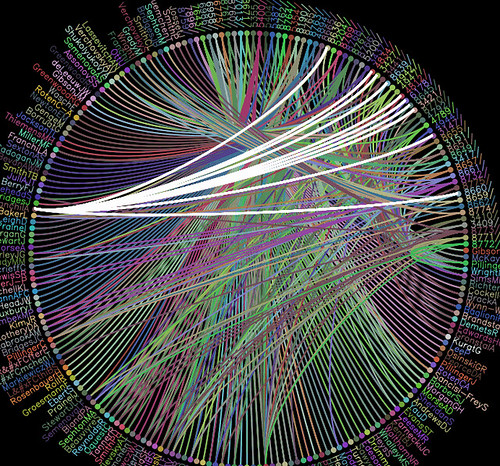
This time, if you hover over the name of an author, the links to the papers they contributed to will be highlighted. If you hover over a paper reference, the authors who contributed to it will be highlighted.
In order to see which authors had coauthored with whom, I guess I'd need to hack the Moowheel code so that if I hovered over an author, the links to papers they had contributed to would be highlighted, and the 'activated' papers would then in turn highlight the links to the authors who had contributed to those papers...
Whilst I haven't tried that approach, I did find another way of visualising who had coauthored with whom - as I'll describe in my next post... :-)
Tags: oro, viz, visualisation, moowheel
 Subscribe...
Subscribe...
